Introduction
I aim to summarize the Attention Is All You Need paper after reading various blogposts and watching paper summary videos.
Machine Language Translation(MLT) Task
Lets start off by taking the example of Machine Language Translation(MLT) Task. Traditionally the approach has been to use RNNs (LSTMs) for this task.
Source-Sentence -> Encoder -> Embeddings -> Decoder -> Dest-Sentence
Source sentence is passed through an RNN Encoder, where the last hidden state is picked as an embeddings and then passed to a Decoder which finally outputs the translated sentence.
Attention Mechanism and Issues with RNNs
Attention mechanism was introduced to improve the performance of RNNs.
Issues with RNNs were :
- Due to the sequentual nature of RNNs, long-range dependences were tough to capture.
- A word goes through multiple hidden states for the translation task.
How Attention Helps ?
- With Attention, the decoder can go back and look into different aspects of the input.
- A decoder can attend to the hidden states of the input sentence. ( h0, h1, h2, h3 .. )
- Pathway to input is much shorter rather than going through all the inputs.
Basic idea is that a decoder in each step would output a bunch of keys. [d] - k1 , k2, k3 .. …. Kn ( these keys would index the hidden states via softmax architecture )
Transformer Architecture
The paper proposes the Transformer architecture which has two components :
- Encoder
- Decoder
![]()
The Source-Sentence goes in the Inputs and the part of the sentence translated till now goes in the Outputs part.
- Every step in producing the next output is one training sample.
- No multi-step backpropagation as in RNNs.
Components of the Transformer :
- Input and Output Embeddings are symmetrical.
- Position Encoding : Encodes where the words are i.e positions of the words.
Attention Blocks
There are a total of 3 attention blocks in the model :
- One Attention Block in the Encoder : This block picks and chooses which words to look at.
-
Two Attention blocks in the Decoder :
The second attention block is interesting since it combines both the Source Sentence and the Target Sentence produced so far.
3 connections go into it, 2 from the Encoder, and one from the decoder.
The 3 connections are :
- Keys(K) - Output of the encoding part of Source Sentence
- Values(V) - Output of the encoding part of Source Sentence
- Queries(Q) - Output of the encoding part of Target Sentence

Q and K have a dot product. In most cases in high dimensions, they will be at 90 degrees and their dot-products will be zeroes. But if the vectors are aligned ( in the same direction), their dot-product will be high ( non-zero). Dot-product is basically the angle between two vectors.

We have a bunch of keys and each key has an associated value.
- We compute the dot-product of the Queries(Q) with each of the keys and then a softmax over it.
- We select the Key which aligns well with the Query and we multiply the softmax with the Values.
softmax(<K|Q>) is a kind of indexing scheme to pick the appropriate value.
Q - I would like to know certain things.
K - They are indexes.
V - They have the attributes.
Intuition
- The Encoder of the source sentence discovers interesting things and then builds key-value pairs.
- The Encoder of the target sentence builds Queries. (Q)
- Together they give the next signal.
High Level Summary
- Attention reduces the path length and is one of the main reasons why it should work better.
- Attention mechanism helps reduce the amount of computation steps that information has to flow from one point of the network to another.
Understanding Self-Attention
Step 1
Encoders Input Vectors - A vector for each word
For each word, we create a :
- Query vector
- Key vector
- Value vector
Vectors are created by multiplying the embedding with 3 matrices that we trained which are W(q), W(k), W(v).
- Input dimensions : 512
- Output : 64
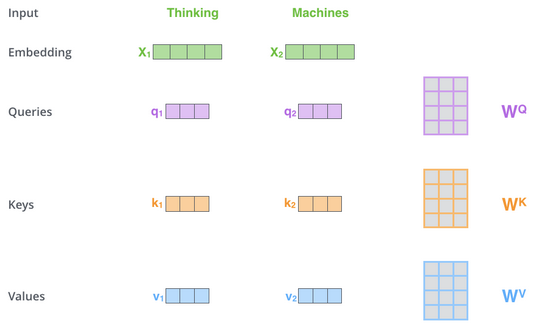
- Multiplying X1 by the WQ weight matrix produces q1, the “query” vector associated with that word.
- We end up creating a “query”, a “key”, and a “value” projection of each word in the input sentence.
Step 2
- To calculate a score.
- We score each word of the input sentence with every other word in the sentence.
/sqrt(qk)")
If there are n words in a sentences with keys (k1, k2, k3 ….. kn) then the score is calculated for each word as follows :
–> q1 * k1, q1 * k2, q1 * k3 …. q1 * kn
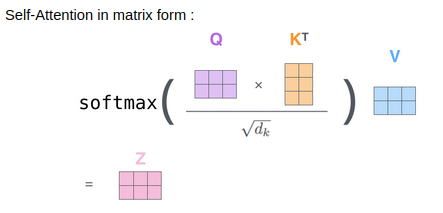
Matrix Calculation of Self-Attention
- Packing our embeddings into a matrix X.
- Multiplying it by weight matrices, WQ, WK, WV.
Understanding Multi-Headed-Attention
Multi headed means we have multiple sets of Q/K/V weight matrices. Transformer uses 8 sets for each encoder/decoder :
- Used to project the input embeddings into a different representation subspace.

Diagram below summarizes the complete multi-headed attention process.

Representing The Order of the Sequence Using Positional Encoding
- Add a vector to each input embedding.
- These vectors follow a specific pattern that the model learns, which helps it determine the exact position of each word.
Other Aspects
- There is a residual block to each of the encoder blocks.
- Difference in the Decoder’s Attention Block :
- Self attention layer is only allowed to attend to earlier positions in the output sequence.
- Future positions are masked(by setting to -inf) before the softmax step.
- The Linear Layer projects decoder output to vector embedding which is equal to the vocabulary size.
References
The first half of this blog post are notes from Yannic’s video explanation and the remaining parts are taken from The Illustrated Transformer blog.
- Video Explanation by Yannic Kilcher : YouTube Link
- The Illustrated Transformer by Jay Alammar : Blog
- Attention Is All You Need paper.
- The Annotated Transformer by harvardnlp is also a great resource which is a “annotated” version of the paper in the form of a line-by-line code implementation.